SQL Interview Questions & Answers That May Help You To Crack Your SQL Interview
SQL is a most common database technology used by many tech companies. If you are preparing for SQL Interview, these SQL Interview Questions & Answers will help you to crack your Interview.

Are you ready to take your SQL Developer interview and looking for SQL Interview Questions? You’re at the right spot. This guide will allow you to brush up on your SQL abilities, boost confidence, and prepare for your next job!
You will find an array of real-world Interview questions from organizations such as Google, Oracle, Amazon, Microsoft, and many more. Each question has an answer that is written in line, which will save you interview time.
Additionally, it covers exercises to help you comprehend the basics of SQL.
SQL Interview Questions
-
What exactly is Database?
A database is an organized data set kept and accessible digitally from a local or remote computer system. They can be large and complicated, and these databases are created with a fixed design and modeling methods.
-
What exactly is DBMS?
DBMS refers to Database Management System. DBMS is a software system responsible for creating, retrieving, updating, and administering databases. It makes sure that the information is organized, consistent and accessible through its connection between the Database’s Database as well as its users or applications software.


-
How does RDBMS work? What is its difference from DBMS?
RDBMS refers to Relational Database Management System. The main difference in this in comparison to DBMS is that RDBMS records information in the form of tables, and also, relations can be created between the fields common to these tables. Most modern database management systems, such as MySQL, Microsoft SQL Server, Oracle, IBM DB2, and Amazon Redshift, are built on RDBMS.
-
What exactly is SQL?
SQL is a short form in form of Structured Query Language. It is the language of choice for relational database management systems. It is particularly helpful in managing organized data composed of entities (variables) and relationships between the various data types.
-
How can you tell the differences between SQL as well as MySQL?
SQL is a common language to retrieve and manipulate structured databases. In contrast, MySQL is a relational database management system similar to SQL Server Oracle and IBM DB2 and IBM DB2 that helps manage SQL databases.
-
What are Tables and Fields?
A table is a logical storage of data in columns and rows. Columns can be classified as vertical, while rows are horizontal. The columns of tables are known as fields, while rows could be called records.
-
What are the constraints in SQL?
Constraints are used to define the rules for data that are contained within the table. They can be used for one or more fields within an SQL table when it is created or after it has been created with the command ALTER TABLE. The restrictions are:
- Not NULL – Prevents NULL value from being put into the column.
- CHECK verifies that all matters within the field align with a particular requirement.
- DELETE – automatically sets a default when no value is specified in the specified area.
- Unique – Enables unique values to be inserted within the form.
- INDEX Indexes fields which makes it easier to retrieve records.
- PRIMARY key – Uniquely identifies every record in tables.
- FOREIGN Key – Assures the integrity of the referential for documents in a different table.
-
Is there a primary Key?
The primary KEY constraint is unique and uniquely identifies every table row. It should contain unique values, and an implied NOT NULL control. A table in SQL is strictly limited to only having one primary key. This comprises one field or several fields (columns).
CREATE TABLE Students ( /* Create table with a single field as primary key */ ID INT NOT NULL Name VARCHAR(255) PRIMARY KEY (ID) ); CREATE TABLE Students ( /* Create table with multiple fields as primary key */ ID INT NOT NULL LastName VARCHAR(255) FirstName VARCHAR(255) NOT NULL, CONSTRAINT PK_Student PRIMARY KEY (ID, FirstName) ); ALTER TABLE Students /* Set a column as primary key */ ADD PRIMARY KEY (ID); ALTER TABLE Students /* Set multiple columns as primary key */ ADD CONSTRAINT PK_Student /*Naming a Primary Key*/ PRIMARY KEY (ID, FirstName);
-
What is a UNIQUE constraint?
A UNIQUE constraint makes sure that the values of the column are unique. This ensures the uniqueness of the column(s) and aids in identifying each row individually. Contrary to primary keys, they can have multiple unique constraints that can be defined for each table. The syntax used for Unique is very identical to the syntax used for PRIMARY KEY and is employed interchangeably.
CREATE TABLE Students ( /* Create table with a single field as unique */ ID INT NOT NULL UNIQUE Name VARCHAR(255) ); CREATE TABLE Students ( /* Create table with multiple fields as unique */ ID INT NOT NULL LastName VARCHAR(255) FirstName VARCHAR(255) NOT NULL CONSTRAINT PK_Student UNIQUE (ID, FirstName) ); ALTER TABLE Students /* Set a column as unique */ ADD UNIQUE (ID); ALTER TABLE Students /* Set multiple columns as unique */ ADD CONSTRAINT PK_Student /* Naming a unique constraint */ UNIQUE (ID, FirstName);
-
What’s a Foreign Key?
A FOREIGN KEY is one or a collection of fields within an individual table that refers to the primary KEY in a different table. Foreign vital constraints ensure the integrity of the relationship between tables.
The table subject to the constraint on foreign keys is marked the child table, and the table that holds the critical candidate is identified as the parent or referenced table.
CREATE TABLE Students ( /* Create table with foreign key - Way 1 */ ID INT NOT NULL Name VARCHAR(255) LibraryID INT PRIMARY KEY (ID) FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID) ); CREATE TABLE Students ( /* Create table with foreign key - Way 2 */ ID INT NOT NULL PRIMARY KEY Name VARCHAR(255) LibraryID INT FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID) ); ALTER TABLE Students /* Add a new foreign key */ ADD FOREIGN KEY (LibraryID) REFERENCES Library (LibraryID);
-
What is Self-Join?
Self-JOIN a self-join is a type of regular join in which the table is joined to itself by an association between the table’s column(s). Self-join is a type of join that uses the INNER LEFT JOIN or JOIN clause and the table alias to assign various names to the table in the query.
SELECT A.emp_id AS "Emp_ID",A.emp_name AS "Employee", B.emp_id AS "Sup_ID",B.emp_name AS "Supervisor" FROM employee A, employee B WHERE A.emp_sup = B.emp_id;
-
What is Cross-Join?
Cross-join is defined as a cartesian product from the two tables in the join. The table that follows join has the same amount of rows as the cross-product of the number of rows between the two tables. If a WHERE condition is employed in cross-join, the query works as an INNER join.
SELECT stu.name, sub.subject FROM students AS stu CROSS JOIN subjects AS sub;
-
What exactly is an Index? Discuss the different types of Indexes.
An index in a database is a data structure that provides a quick search of data within one or more columns in tables. It improves performance when accessing the data in a database table but at the expense of other writing and memory to keep the index’s data structure.
CREATE INDEX index_name /* Create Index */ ON table_name (column_1, column_2); DROP INDEX index_name; /* Drop Index */
-
What is the main difference between Clustered Index and Non-clustered?
As previously explained, The differences can be broken down into three minor elements Three factors.
- Clustered index alters the way that records are saved in a database based on the column that has been indexed. Non-clustered indexes create an independent entity within the table, which refers to the table that it was initially.
- The clustered index is utilized to speed up and quickly retrieve database data, while retrieving data from the unclustered index is slow.
- The Database could be a single clustered index for SQL tables and contain several non-clustered indexes.
-
What exactly is Data Integrity?
Data Integrity assures the accuracy and reliability of the data throughout its entire life cycle and is an essential element in the design of the system, its implementation, and the use of any system that manages stores, and retrieves data. It also establishes integrity constraints to ensure that business rules adhere to the data once it has been added to an application or Database.
-
What’s the Query?
An inquiry is a request to retrieve information or data from a table in a database or a combination of tables. A query for a database could be either a query that is a select or an action query.
SELECT fname, lname /* select query */ FROM myDb.students WHERE student_id = 1;
UPDATE myDB.students /* action query */ SET fname = 'Captain', lname = 'America' WHERE student_id = 1;
-
What is Subquery? What are the types of Subqueries?
Subqueries are within another query, referred to as interspersed or inner queries. It is utilized to limit or increase the amount of data the primary question can access, thereby limiting or improving the results of a direct query. For instance, in this case, we get the contact information for students who have registered in the maths subject.
SELECT name, email, mob, address FROM myDb.contacts WHERE roll_no IN ( SELECT roll_no FROM myDb.students WHERE subject = 'Maths');
The subquery has two kinds of subqueries: correlated and non-correlated.
- A related subquery can’t be regarded to be an independently-defined query. However, it could reference the table column in the primary questions FROM.
- An HTML0 Non-correlated subquery is regarded to be an individual query. Its output is used to replace the production of the primary question.
- What do they mean by UNION, MINUS, and INTERSECT commands?
The UNION operator blends and returns the result set retrieved from two or more select statements.
The MINUS operator within SQL can eliminate duplicates in the result set compiled from the second query. It filters the results obtained through the first SELECT query and then returns results filtered by the first.
The INTERSECT clause of SQL blends the result set obtained by two SELECT statements, where the results from one match those from the other and returns this intersection of the result sets.
Specific requirements must be satisfied before the execution of either or both of these statements using SQL –
- Each SELECT information inside the clause should contain the same number of columns
- The columns should be of similar types of data
- The columns in every SELECT view must have the same order.
-
What is a Cursor? What is the best way to use Cursor?
The database cursor can be described as a structure that permits the traversal of records within databases. Cursors also aid in processing following traversal, for example, retrieval, adding to the removal of database records. They are viewed as a way to point to a row within a set of rows.
working in conjunction with SQL Cursor
- CLARE a cursor following any declaration of variables. The order of a cursor must be accompanied by a statement of SELECT.
- Open the Cursor to start the results collection. The OPEN statement should be executed before fetching rows from the result set.
- FETCHstatement to search for and then move on to the following row of results.
- Make to the CLOSE statement to stop your Cursor.
- Then utilize the DEALLOCATE statement to erase the definition of the Cursor and free the resources associated with it.
- Check out the various types of relationships that are available in SQL.
DECLARE @name VARCHAR(50) /* Declare All Required Variables */
DECLARE db_cursor CURSOR FOR /* Declare Cursor Name*/
SELECT name
FROM myDB.students
WHERE parent_name IN ('Sara', 'Ansh')
OPEN db_cursor /* Open cursor and Fetch data into @name */
FETCH next
FROM db_cursor
INTO @name
CLOSE db_cursor /* Close the cursor and deallocate the resources */
DEALLOCATE db_cursor
- One-to-one is the relationship between two tables, wherein every record from one table can be linked with the maximum number of history in the table to the opposite.
- One-to-Many and Many-to-One The most widely used relation is where particular records in the table can be associated with multiple documents from the table to which it is linked.
- Many-to-Many This is employed when multiple instances on both sides are required to establish the relationship.
- Self-referencing relationships – This is when tables need to establish a relationship with themselves.
-
What’s Normalization?
Normalization is the process of arranging structured data in the Database effectively. It includes the construction of tables, creating relationships to them and creating rules for these relationships. Redundancy and inconsistent data are controlled using these rules, thereby providing flexibility to databases.
- What exactly is denormalization?
Denormalization is the reverse process to normalization. In this process, the normalized schema transforms into a schema with redundant data. Performance is improved by making use of redundancy, and by making sure that the redundant data is consistent. The denormalization is to reduce the amount of overhead created in the query processor due to being over-normalized.
-
What is the difference between DROP or TRUNCATE statements?
If a table is deleted, the table’s associated items are removed too. This includes the relationships that are defined in the table’s relation to other tables, integrity checks and restrictions, access privileges, and any other rights that the table is granted. To create and utilize the table in its original format, the entire set of relations and constraints checks privileges, and relationships must be rewritten. If the table is cut down, it is not affected by the above issues arise, and the table remains in its original form.
Also Read:
- Deltax Interview Questions – How To Crack Deltax Interview
- Top 50 ES6 Interview Questions & Answers
- 30+ Most Asked AWS Lambda Interview Questions
- 20+ Most Asked Flask Interview Questions
- Terraform Interview Questions & Answers For Interview Preparation
- 12 Top Autosar Interview Questions That Can Help To Crack Your Interview
-
How can you tell the differences between the DELETE or TRUNCATE statements?
The TRUNCATE command can be used to remove all rows in the table and clear the space that is occupied by the table.
It is a command that deletion command only deletes rows of the table according to the condition specified in the where clause, or erases all rows of the table even if no conditions are set. However, it doesn’t free the table’s space.
-
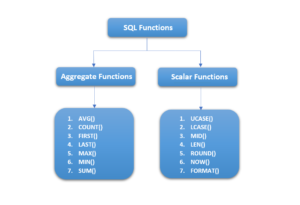
What are the Aggregate and Scalar roles?
Aggregation performs operations on a set of values, resulting in one scalar number. These functions are typically utilized in conjunction with the GROUP BY clause and the HAVING clause of the statement. These are the most frequently employed SQL aggregate function:
- AVG() – Calculates the mean of a group of data.
- COUNT() – Counts the total number of records contained in the table or view of.
- Min() – Calculates the minimum of numbers.
- MAX() – Calculates the highest value of a set of data.
- SUM() – Calculates the sum of a group of numbers.
- FIRST() – Fetches the first element of an array of data.
- LAST() – Fetches the final part of an array of numbers.
NOTE: All aggregate functions discussed above ignore NULL values, except the COUNT function.
A scalar function produces a unidimensional value that is dependent on the input. These are the most frequently employed SQL functions for scalars:
- LEN() – Calculates the length of the area (column).
- UCASE() – Converts the string values to characters that are uppercase.
- LCASE() – Converts strings into lowercase letters.
- Mid() – Extracts substrings from string values contained in the form of a table.
- CONCAT() – Concatenates two or more strings.
- RAND() – Generates random numbers with a specified length.
- ROUND() – Calculates the round-off integer value of a numeric field (or decimal points value).
- “NOW”() – Returns the current date and time.
- FORMAT() – Sets the design for displaying the values in a set.
-
What is the User-defined function? What are its different types?
SQL’s user-defined functions are like those in other programming languages that accept parameters, execute complicated calculations, and return the result. They are designed to utilize logic in a repetitive manner whenever it is needed. There are two kinds of SQL user-defined functions:
- Scalar Function we have explained previously that user-defined scalar functions produce only one scalar.
- Table-Valued Functions: Table-valued functions that are user-defined return tables as an output.
- Inline provides a data table type that is based on simple SELECT.
- Multi-statement results in a tabular set of results; however, unlike inline multiple SELECT statements, they can be utilized within the function’s body.
-
What exactly is OLTP?
OLTP is a shorthand in the sense of Online Transaction Processing, an area of the software that can support transaction-oriented software. One of the essential characteristics of an OLTP program is the capacity to ensure that concurrency is maintained. To prevent one-off failures, OLTP systems are often distributed. They are generally built to handle a lot of users performing brief transactions. Database queries are usually uncomplicated, require minimal response time, and produce only a few records. Here’s a look at the functioning of an OLTP system.
-
What’s Collation? What are the various types that are Collation sensitive?
Collation is an established set of rules that govern the method by which data is sorted and to be compared. Rules that define the proper sequence of characters are employed to sort feelings. It includes options to specify the sensitivity of the case, accent marks, kana-type characters, and the width of characters. Here are the various types of collation sensitiveness:
- Sensitivity to the case: It is important to note that a and A are treated differently.
- The accent sensitivity of The words as well as the is treated differently.
- Kana Sensitivity: Japanese kana characters Hiragana and Katakana are treated differently.
- The width sensitivity The same character is represented as the single-byte (half-width) and the double-byte (full-width), which are considered differently.




